什么是搜索
本文共 682 字,大约阅读时间需要 2 分钟。
一、搜索
什么是搜索, 计算机根据用户输入的关键词进行匹配,从已有的数据库中摘录出相关的记录反馈给用户。
常见的全网搜索引擎,像百度、谷歌这样的。但是除此以外,搜索技术在垂直领域也有广泛的使用,比如淘宝、京东搜索商品,万芳、知网搜索期刊,csdn中搜索问题贴。也都是基于海量数据的搜索。 1 如何处理搜索 1.1用传统关系性数据库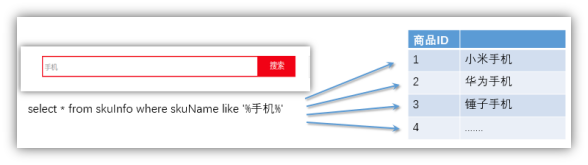
弊端:
1、 对于传统的关系性数据库对于关键词的查询,只能逐字逐行的匹配,性能非常差。 2、匹配方式不合理,比如搜索“小密手机” ,如果用like进行匹配, 根本匹配不到。但是考虑使用者的用户体验的话,除了完全匹配的记录,还应该显示一部分近似匹配的记录,至少应该匹配到“手机”。1.2专业全文索引是怎么处理的
全文搜索引擎目前主流的索引技术就是倒排索引的方式。 传统的保存数据的方式都是 记录→单词 而倒排索引的保存数据的方式是 单词→记录 例如 搜索“红海行动” 但是数据库中保存的数据如图:
那么搜索引擎是如何能将两者匹配上的呢?
基于分词技术构建倒排索引: 首先每个记录保存数据时,都不会直接存入数据库。系统先会对数据进行分词,然后以倒排索引结构保存。如下:
然后等到用户搜索的时候,会把搜索的关键词也进行分词,会把“红海行动”分词分成:红海和行动两个词。
这样的话,先用红海进行匹配,得到id=1和id=2的记录编号,再用行动匹配可以迅速定位id为1,3的记录。 那么全文索引通常,还会根据匹配程度进行打分,显然1号记录能匹配的次数更多。所以显示的时候以评分进行排序的话,1号记录会排到最前面。而2、3号记录也可以匹配到。转载地址:http://tuzki.baihongyu.com/
你可能感兴趣的文章
Spring Batch 环境设置
查看>>
字符组转译序列
查看>>
字符转译序列
查看>>
Java 数据类型
查看>>
UTF-16 编码简介
查看>>
Java 变量名
查看>>
Java 四舍五入运算
查看>>
Spring Batch 例子: 运行系统命令
查看>>
解析输入
查看>>
格式化输出
查看>>
Java 大数值
查看>>
括号及后向引用
查看>>
Spring Batch 核心概念
查看>>
Spring Batch 例子: 导入分隔符文件到数据库
查看>>
非贪婪匹配
查看>>
Spring Batch 例子: 导入定长文件到数据库
查看>>
匹配时刻
查看>>
为数值添加逗号
查看>>
忽略大小写匹配
查看>>
全局匹配模式
查看>>